Concurrency and Goroutines: Understanding Concurrency and Goroutines in Go
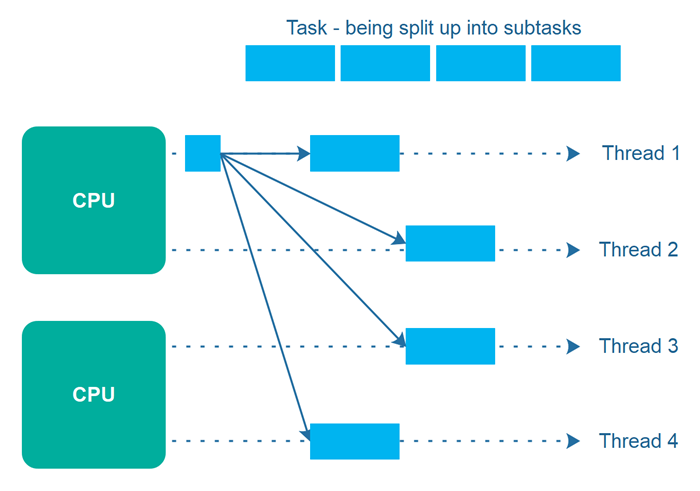
Concurrency is an essential concept in modern programming, allowing multiple tasks to run concurrently and efficiently utilize system resources. Go, a statically typed programming language developed by Google, provides built-in support for concurrency through Goroutines and channels. In this tutorial, we will explore how to leverage Goroutines and manage concurrency using GoLand, a popular integrated development environment (IDE) for Go.
1. Introduction to Concurrency in Go
Concurrency is the ability of a program to perform multiple tasks simultaneously, making efficient use of system resources such as CPU cores. Go introduces concurrency as a core language feature, enabling developers to write concurrent programs easily and efficiently.
Go achieves concurrency through Goroutines, which are lightweight concurrent execution units, and channels, which provide synchronization and communication between Goroutines.
2. Goroutines: Lightweight Concurrent Execution Units
A Goroutine is a function that can be executed concurrently with other Goroutines. They are lightweight and have a smaller memory footprint compared to operating system threads. Goroutines are managed by the Go runtime, allowing efficient scheduling and execution of concurrent tasks.
The go keyword is used to start a new Goroutine. When a Goroutine is created, it runs concurrently with the main Goroutine or other Goroutines, allowing parallel execution.
3. Creating and Running Goroutines
Let’s dive into some code examples to see how Goroutines are created and run in Go. Assume we have a function process() that performs some time-consuming task.
func process() {
// Perform some time-consuming task
}
To execute this function concurrently using a Goroutine, we can use the go keyword:
go process()
The go keyword launches a new Goroutine, and process() will start executing concurrently. The main Goroutine and the newly created Goroutine will run independently.
4. Synchronization with Channels
Channels in Go provide a mechanism for Goroutines to communicate and synchronize their execution. A channel is a typed conduit that allows sending and receiving values between Goroutines.
Let’s consider an example where we have two Goroutines: a producer and a consumer. The producer generates some data and sends it to the consumer using a channel.
func producer(ch chan<- int) {
for i := 0; i < 5; i++ {
ch <- i // Send data to the channel
}
close(ch) // Close the channel to signal the end of data
}
func consumer(ch <-chan int) {
for num := range ch {
fmt.Println(num) // Print the received data
}
}
In this example, the producer Goroutine sends integers to the channel ch, and the consumer Goroutine receives and prints them. The ch channel is created with the type chan int, indicating it can only send or receive integers.
To execute the producer and consumer concurrently, we can create a channel and launch the Goroutines using the go keyword:
ch := make(chan int)
go producer(ch)
go consumer(ch)
The producer Goroutine sends data to the channel, and the consumer Goroutine receives and prints it. This synchronization ensures that the consumer only processes data when it is available.
5. GoLand’s Tools for Managing Goroutines
GoLand, an IDE developed by JetBrains, provides powerful tools to manage Goroutines and visualize concurrent execution.
Debugging Goroutines
GoLand offers a rich set of debugging features for Goroutines. You can set breakpoints, inspect variables, and step through Goroutines to identify and fix issues in concurrent code.
To debug Goroutines in GoLand, follow these steps:
- Set a breakpoint in the code where you want to start debugging.
- Run the program in debug mode by clicking on the “Debug” button or using the corresponding keyboard shortcut.
- When the breakpoint is hit, the program execution will pause.
- Use the debugging toolbar to step through the code, inspect variables, and analyze Goroutine behavior.
Goroutine Visualization
Understanding the flow of Goroutines and how they interact can be challenging in complex concurrent programs. GoLand provides a visual Goroutine tool that helps you analyze the Goroutine execution flow.
To visualize Goroutines in GoLand, follow these steps:
- Run your program in debug mode.
- Open the “Goroutines” tab in the Debug tool window.
- The “Goroutines” tab displays a list of active Goroutines and their current state.
- You can see the Goroutine stack traces, examine their state, and navigate through them to understand the execution flow.
Profiling Goroutines
Profiling is crucial for optimizing performance in concurrent programs. GoLand integrates with Go’s profiling tools to help you analyze Goroutine behavior and identify bottlenecks.
To profile Goroutines in GoLand, follow these steps:
- Open the “Run” menu and select “Profile”.
- Choose the profiling type you want, such as CPU profiling or memory profiling.
- Run your program with the selected profiling configuration.
- GoLand will collect profiling data and present it in an interactive UI.
- Analyze the Goroutine-specific profiling results to identify performance issues and optimize your code.
Concurrency and Goroutines are fundamental to writing efficient and scalable programs in Go. With GoLand’s powerful tools for managing Goroutines, you can debug, visualize, and profile concurrent code effectively.
In this tutorial, we covered the basics of concurrency and Goroutines in Go, including creating and running Goroutines, synchronizing with channels, and leveraging GoLand’s tools for managing Goroutines. Armed with this knowledge, you can confidently write concurrent programs in Go and utilize GoLand’s features to enhance your development workflow.
Remember, concurrency can be complex, so it’s important to understand the principles and best practices to write correct and efficient concurrent code. Keep exploring the vast possibilities of Goroutines and Go’s concurrency features to build robust and highly performant applications.